|
|
Survey of Autoregressive Models for Image and Video Generation
Saqib Azim, Mehul Arora, Narayanan Ranganatha, Mahesh Kumar
abstract / report
This survey paper offers a comprehensive overview of recent advances in autoregressive (AR) models for image and video generation. It discusses state-of-the-art AR models like PixelCNN, PixelRNN, Gated PixelCNN, and PixelSNAIL, emphasizing their unique archi- tectures and contributions. The main challenge in AR models, handling long-range dependencies effectively, is addressed through various approaches, such as gated activations, self-attention mechanisms, and residual blocks. The paper presents Locally Masked Convolution and Autoregressive Diffusion Models as examples of order-agnostic approaches, improving upon traditional autoregressive models. Transformer-based networks are explored for autoregressive image generation, showcasing superior performance in image quality and synthesis tasks. Quantization-based models enhance image diversity and quality through feature quantization and variational regularization. The paper then discusses Autoregressive modeling in pixel space and latent space for video generation. The paper concludes by discussing the strengths, limitations, and future research directions in autoregressive models for image and video generation, providing valuable insights for researchers and practitioners.
|
|
|
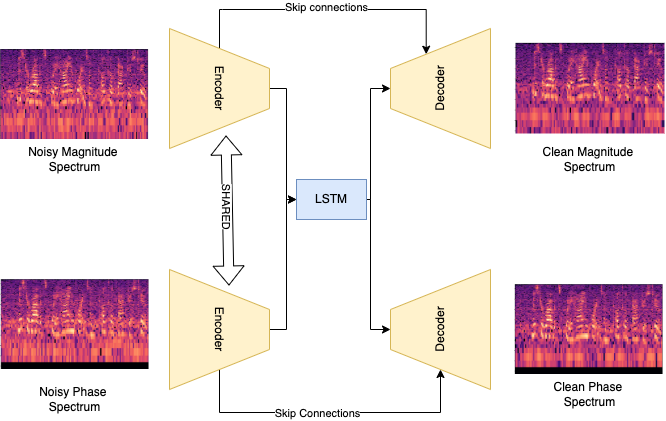
Speech Enhancement using Wavelet-based Convolutional-Recurrent Network
Parthasarathi Kumar, Saqib Azim
abstract / report / presentation
In this project, we present an end-to-end data-driven system for enhancing the quality of speech signals using a convolutional-recurrent neural network. We present a quantitative and qualitative analysis of our speech enhancement system on a real-world noisy speech dataset and evaluate our proposed system's performance using several metrics such as SNR, PESQ, STOI, etc. We have employed wavelet pooling mechanism instead of max-pooling layer in the convolutional layer of our proposed model and compared the performances of these variants. Based on our experiments, we demonstrate that our model's performance on noisy speech signals using haar wavelet is better than when using max-pooling. In addition, wavelet based approach results in faster convergence during training as compared to other variants.
|
|
|
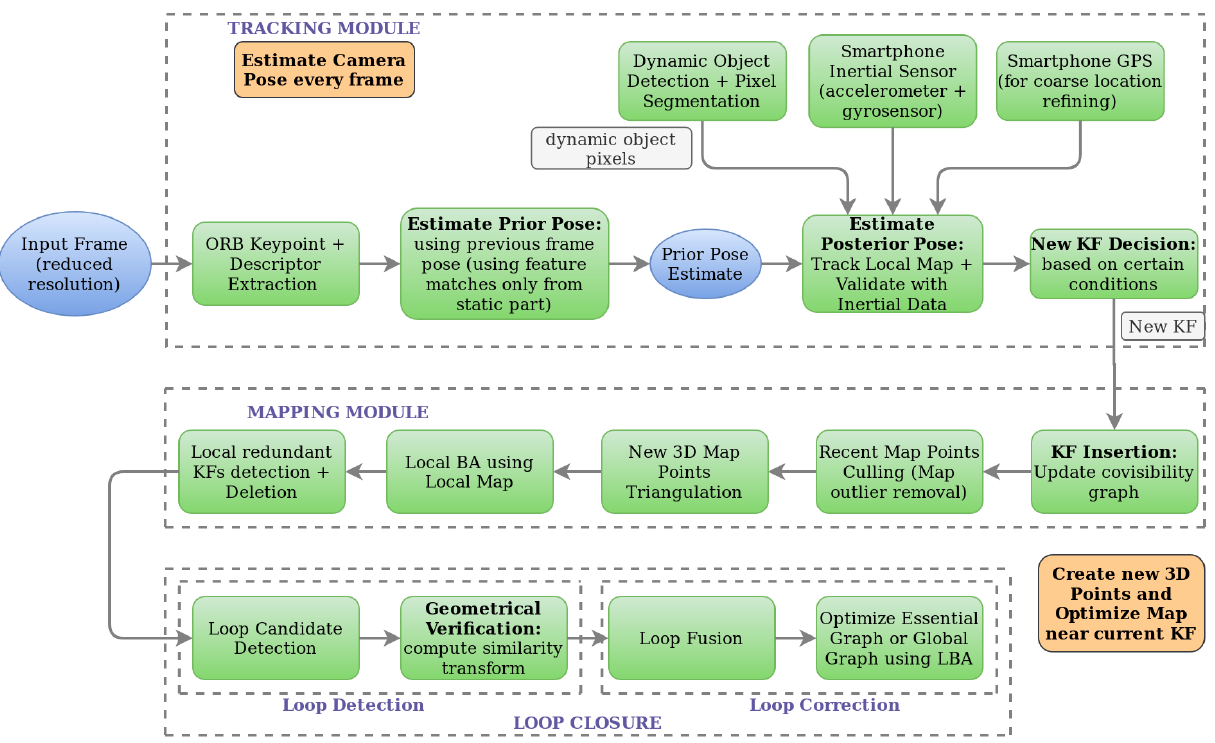
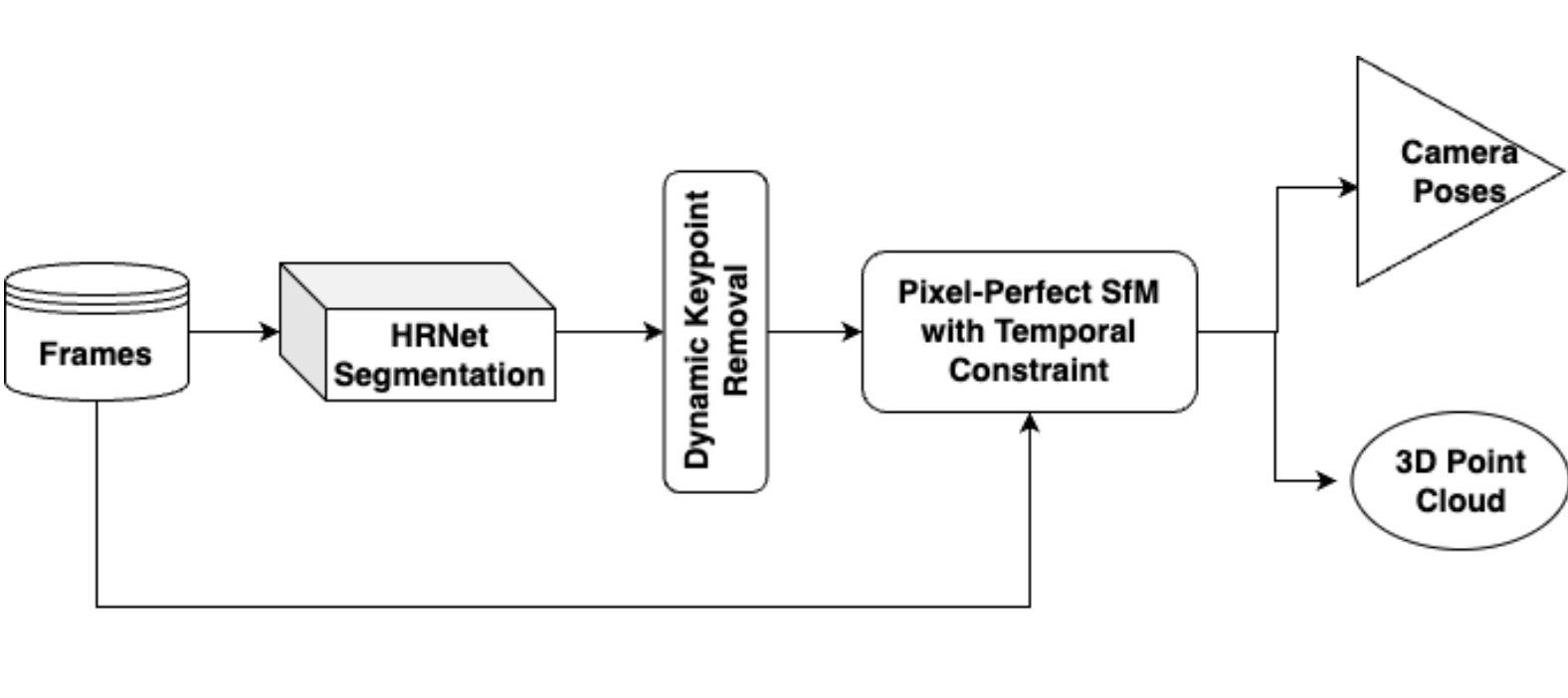
Semantic Temporal Constrained Pose Estimation using Structure-from-Motion
Narayanan Ranganatha, Saqib Azim, Mehul Arora, Mahesh Kumar
abstract / report
The objective of this project is to accurately estimate the 6D poses (position and orientation) of a monocular camera moving in an environment. We present an approach for visual pose estimation using the Structure from Motion (SfM) technique with temporally constrained frame matching and semantic assistance in the context of autonomous driving scenarios. We address the challenge of pose estimation in dynamic scene environments, which can introduce errors due to incorrect matching in the reconstruction of 3D scenes and the estimated trajectory using the SfM algorithm. Specifically, we use visual data from outdoor driving scenarios such as the KITTI dataset to evaluate our approach since accurate estimation of the car's pose in dynamic environments is crucial for autonomous driving applications. Our method contributes to this field by providing reliable and precise car pose information, thus advancing the development of autonomous driving systems.
|
|
|
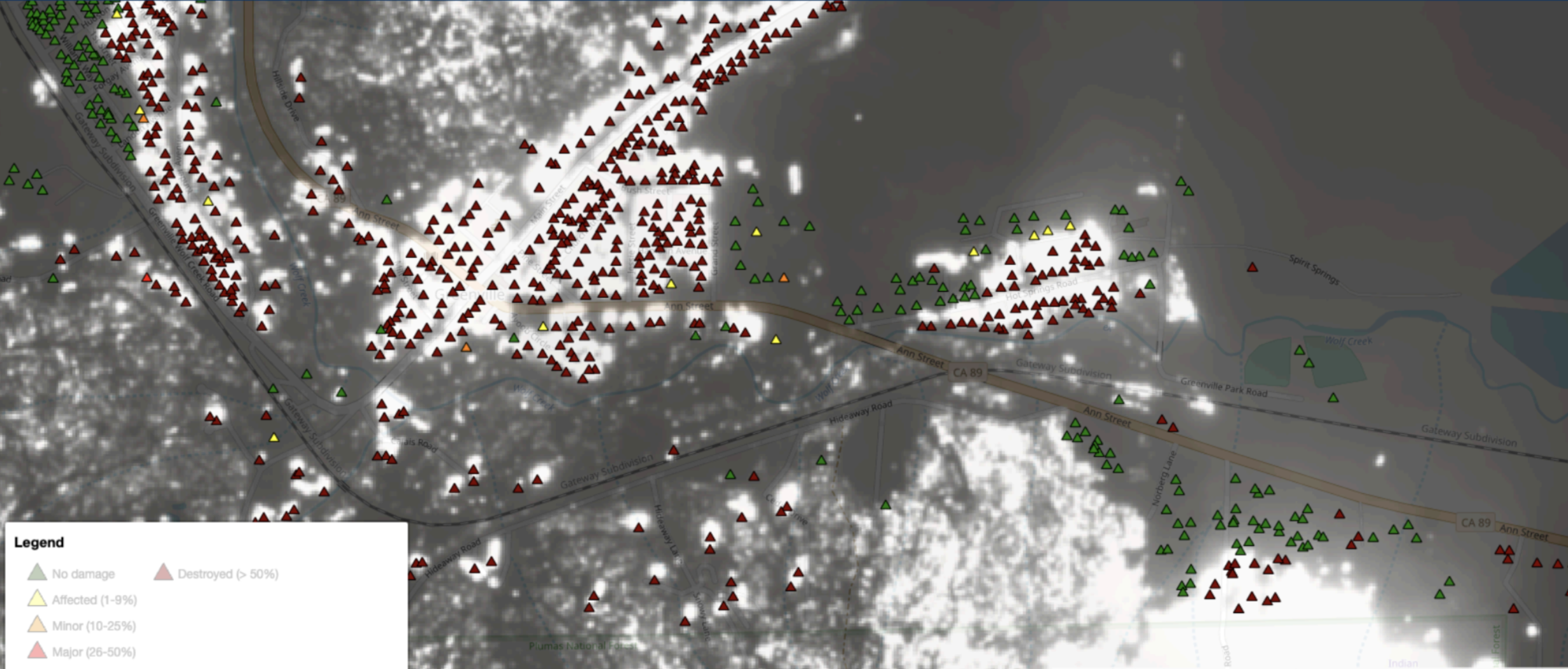
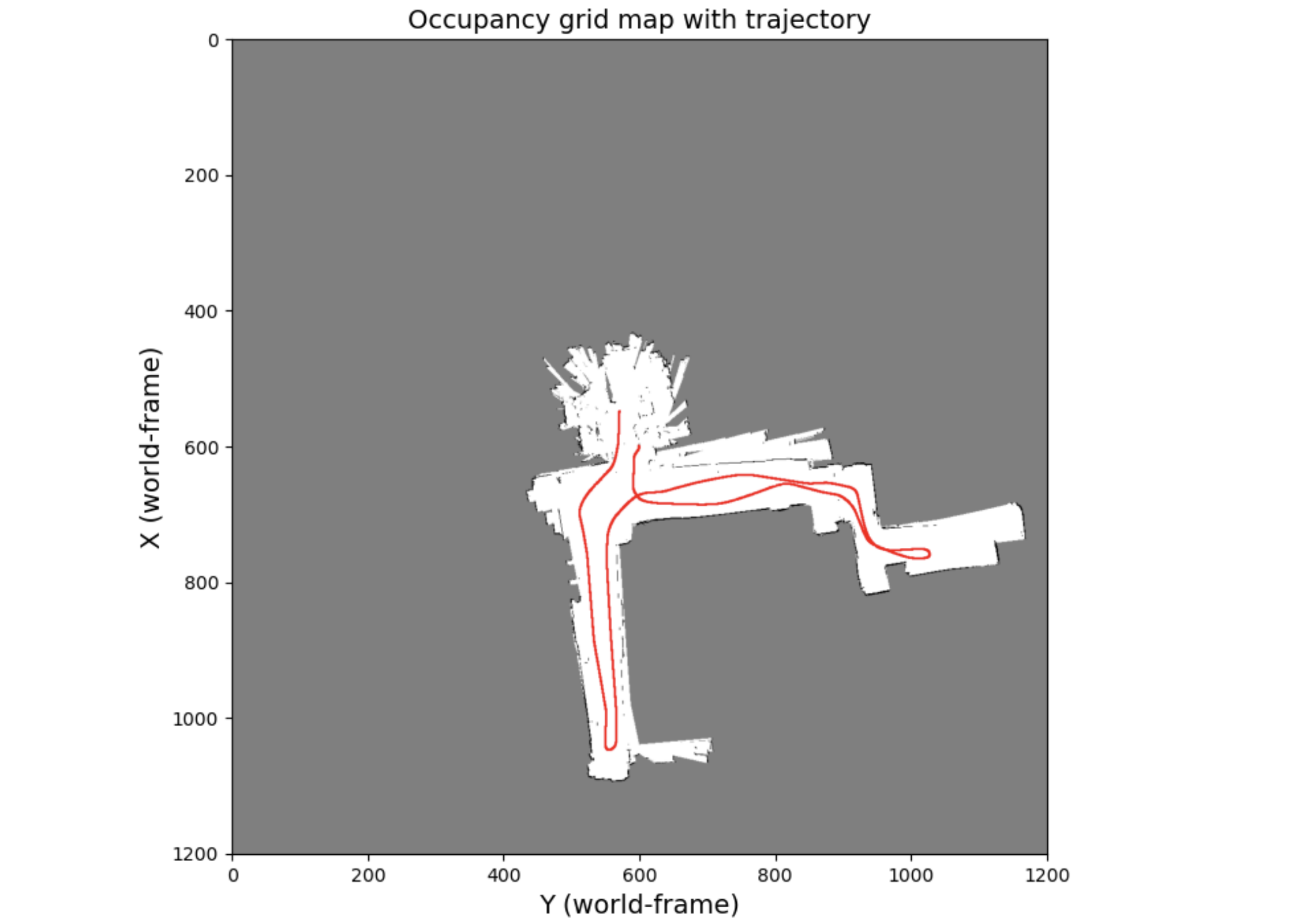
Particle-Filter SLAM and 2D Texture Mapping for Autonomous Navigation
Saqib Azim
abstract / report
In this project, we have successfully developed a SLAM (Simultaneous Localization and Mapping) system that integrates particle filters for concurrent localization and mapping of environments. This system harnesses data from a variety of sensors including encoders, LIDAR, IMU, and an RGBD Kinect camera. The project is structured in two main phases. Initially, we apply a particle filter algorithm for environment localization and mapping, utilizing data solely from LIDAR, encoders, and IMU sensors. In the subsequent phase, we enhance the generated map by adding textural details. This is achieved by incorporating data from the RGBD Kinect camera mounted on the robot, alongside the optimized robot trajectory derived from the particle filter algorithm employed in the first phase. This two-pronged approach allows for a more detailed and accurate representation of the mapped environment.
|
|
|
Proximal Policy Optimization (PPO) PyTorch Implementation
abstract / code
This repository offers a beginner-friendly, modular implementation of Proximal Policy Optimization (PPO) with a clipped objective in PyTorch, supporting both continuous and discrete action spaces. It includes YAML-based configuration for customizable hyperparameters and is compatible with OpenAI Gym environments like CartPole, LunarLander and HalfCheetah, providing a flexible framework for experimenting with reinforcement learning algorithms and adapting to custom environments.
|
|
|
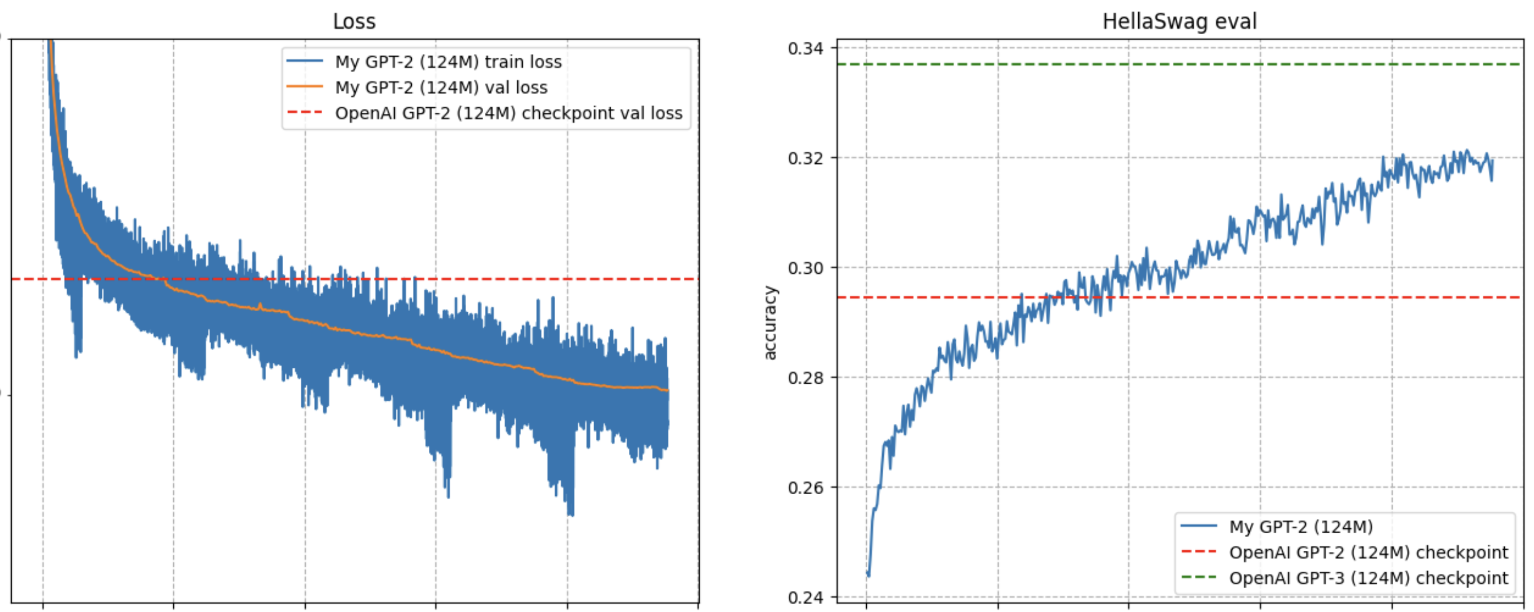
GPT-2 Implementation in PyTorch
abstract / code
This project involves implementing OpenAI's GPT-2 model from scratch in PyTorch, trained on the FineWebEdu dataset. The code is structured modularly, offering customizable hyperparameters for training and inference.
|
|
|
Hazardous Activity Detection in Workplaces using Computer Vision
Saqib Azim, Takumi Nito, Tomokazu Murakami
Accepted at Hitachi Annual Research Symposium 2020
|
|
|
Adversarial Robustness Analysis of Deep Learning Models
Saqib Azim, Lily Weng
summary
We utilized attack methods such as FGSM, PGD, Auto-Attack to generate adversarial examples and conducted an empirical analysis of CLIP model's resilience to adversarial perturbations. I further developed robust CLIP-based classifier against L2-norm perturbations using adversarial training and randomized smoothing and evaluated the robust classifier on CIFAR10 and ImageNet datasets.
|
|
|
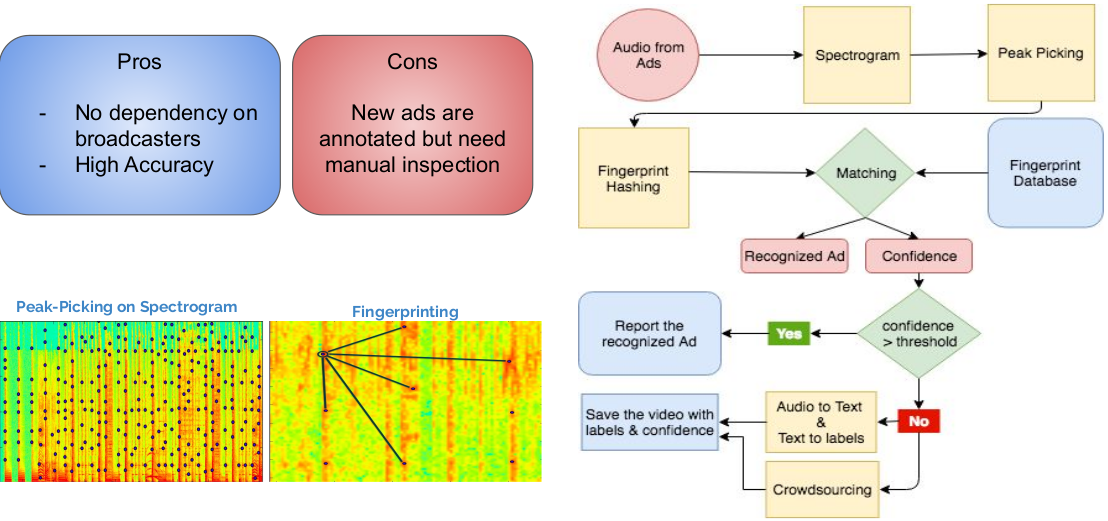
TV Audience Measurement Challenge
Saqib Azim, Pranav Sankhe, Sachin Goyal, Sanyam Khandelwal, Tanmay Patil
Bronze Medal (3rd / 23 teams) at the Inter-IIT Technical Meet 2018
summary / code / presentation
Proposed scalable and robust solutions for various challenges put forward by BARC India such as channel identification, advertisement and content classification and recognition, age and gender recognition of viewers and providing hardware free solution in order to capture TV viewership data of the country
|
|
|
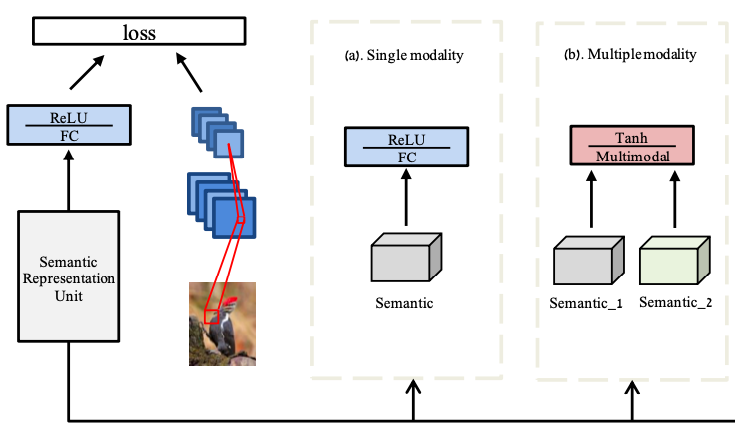
Zero-Shot Learning for Object Recognition
Advisor: Prof. Subhasis Chaudhuri
summary / code
Proposed a semi-supervised VGG16-based encoder-decoder network to learn visual-to-semantic space mapping using novel combination of margin-based hinge-rank loss and Word2Vec embeddings. Explored multiple networks for better visual feature representations. Achieved improvement in recognition performance from 58.7% to 65.3% on the Animals with Attributes dataset over existing methods.
|
|
|
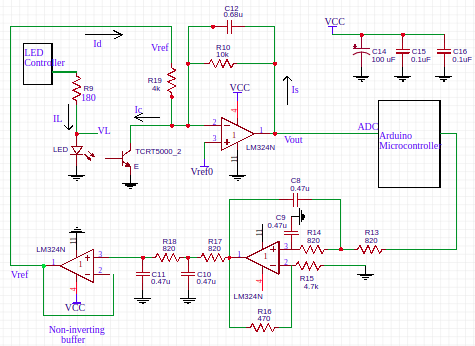
Photoplethysmogram (PPG) Signal Acquisition Module
Saqib Azim, Pranav Sankhe, Ritik Madan
abstract / report
A photoplethysmogram(PPG) is an optically obtained plethysmogram, a volumetric measurement of an organ. With each cardiac cycle the heart pumps blood to the periphery. The change in the volume caused by the blood is detected by illuminating the skin with IR light. We developed and implemented an electronic system to capture and display the PPG signal. We make infrared(IR) light incident on finger tip and measure the reflected IR light using a phototransistor which contains the PPG signal. The raw PPG signal is in the form of current output of the phototransistor, typically [0.2-0.4] mA, and we use a current to voltage converter to get the voltage signal. The raw PPG often has a large slowly varying baseline and it needs to be restored to optimally use the available ADC range. We carry out baseline restoration by controlling the bias voltage of the current injector using a microcontroller. We amplify the signal using a fixed value of gain resistor in the current to voltage converter. We also designed an auto-led intensity control to control the LED current and hence the emitted IR light in an effort to make the acquisition module adaptable to users with varying skin colours, motion artifacts etc. Finally we display the PPG signal on an android smartphone by transmitting the PPG signal over bluetooth.
|